
2장 카프카 환경 구성
2-1. 책의 실습 환경 구성
책에서는 aws 내에서 실습환경을 구성하였으나,
GCP의 무료크레딧을 사용하여 환경을 구성하기로 했다...(금전 이슈ㅠ)
1) 인스턴스 생성
GCP의 인스턴스 그룹을 사용해서 7개의 인스턴스를 통합적으로 생성, 관리하기로 했다.
(아 테라폼 안쓴다 오예)
2) hosts 파일 수정하기 & ansible을 위한 ssh 키 복사
DNS를 사용하기에는 실습환경에서는 굳이라는 생각이 들어 사용하지 않았다.
차라리 그돈으로 일주일 더 학습하는 것이..
그래서 hosts파일을 수정해서 사용하기로 했다.
ansible용으로 하나, 주키퍼 3대, 카프카 3대로 구성했다.
sudo nano /etc/hosts
<내부ip> peter-ansible01.foo.bar
<내부ip> peter-zk01.foo.bar
<내부ip> peter-zk02.foo.bar
<내부ip> peter-zk03.foo.bar
<내부ip> peter-kafka01.foo.bar
<내부ip> peter-kafka02.foo.bar
<내부ip> peter-kafka03.foo.bar
자 이제 ansible으로 카프카를 설치할 것이므로 ssh로 각 인스턴스들을 연결할 수 있도록 해야 한다.
ssh키를 scp 명령을 이용해 ansible 인스턴스에 전송한다.
scp -i keypair.pem keypair.pem key@<ansible01-ip>
키를 보냈다면 사용을 위해서 키의 권한을 조정하고
등록하는 과정이 필요하다.
# 키 권한 조정
chmod 600 keypair.pem
# 키 등록
ssh-agent bash
ssh-add keypair.pem
마지막으로 모든 작업이 끝나면 git을 이용해서 예제 파일을 다운로드 한다.
(실습 환경설정 완료?)
git clone https://github.com/onlybooks/kafka2
2-2. 카프카 클러스터 구성
1) common role 편집 (yum → apt)
책에서는 amazon-linux 또는 centOS를 추천하나 GCE에서 해당 환경이 이용 불가하므로 Ubuntu에서 진행....
이에 yum 코드를 apt를 사용하는 코드로 변경해 주는 작업이 필요했다.
따라서 roles/common/tasks/main.yml 파일을 수정할 필요가 있다.
# 변경 코드
---
- name: Set timezone to Asia/Seoul
timezone:
name: Asia/Seoul
- name: Install Java and tools
apt:
name:
- dstat
- openjdk-8-jdk
- openjdk-8-jdk-headless
- krb5-user
- git
state: latest
update_cache: yes
- name: Copy krb5.conf
template:
src: krb5.conf.j2
dest: /etc/krb5.conf
owner: root
group: root
mode: '0644'
backup: no코드를 변경하고 정상적으로 설치가 진행되었다!
2) 주키퍼 & 카프카 설치
책의 설명대로 주키퍼와 카프카를 설치한다.
실습 파일을 뜯어보면 간단한 코드니까
저자를 위해서 해당 코드는 공개하지 않는다!

2-3. 카프카 맛보기
2장의 마지막에는 카프카 토픽을 생성하고
컨슈머와 프로듀서를 실행해 간단한 실습을 수행하는 부분이 나와있다.
정말 간단하니까 실습을 해보는 것을 추천하고
마지막은 내가 실습했던 사진을 첨부한다.
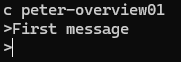
마지막으로 내가 참고했던 글들을 가져왔다.
'Data Engineering > kafka' 카테고리의 다른 글
| kafka > 실전 카프카 개발부터 운영까지 개요 & 1장 (1) | 2024.10.04 |
|---|



